02
Token-budget routesResearch project
Decomposing Reasoning Efficiency
A workshop version of the efficiency accounting idea
Core question
When two models solve similar numbers of reasoning tasks, which one spends fewer generated tokens per solved instance?
01
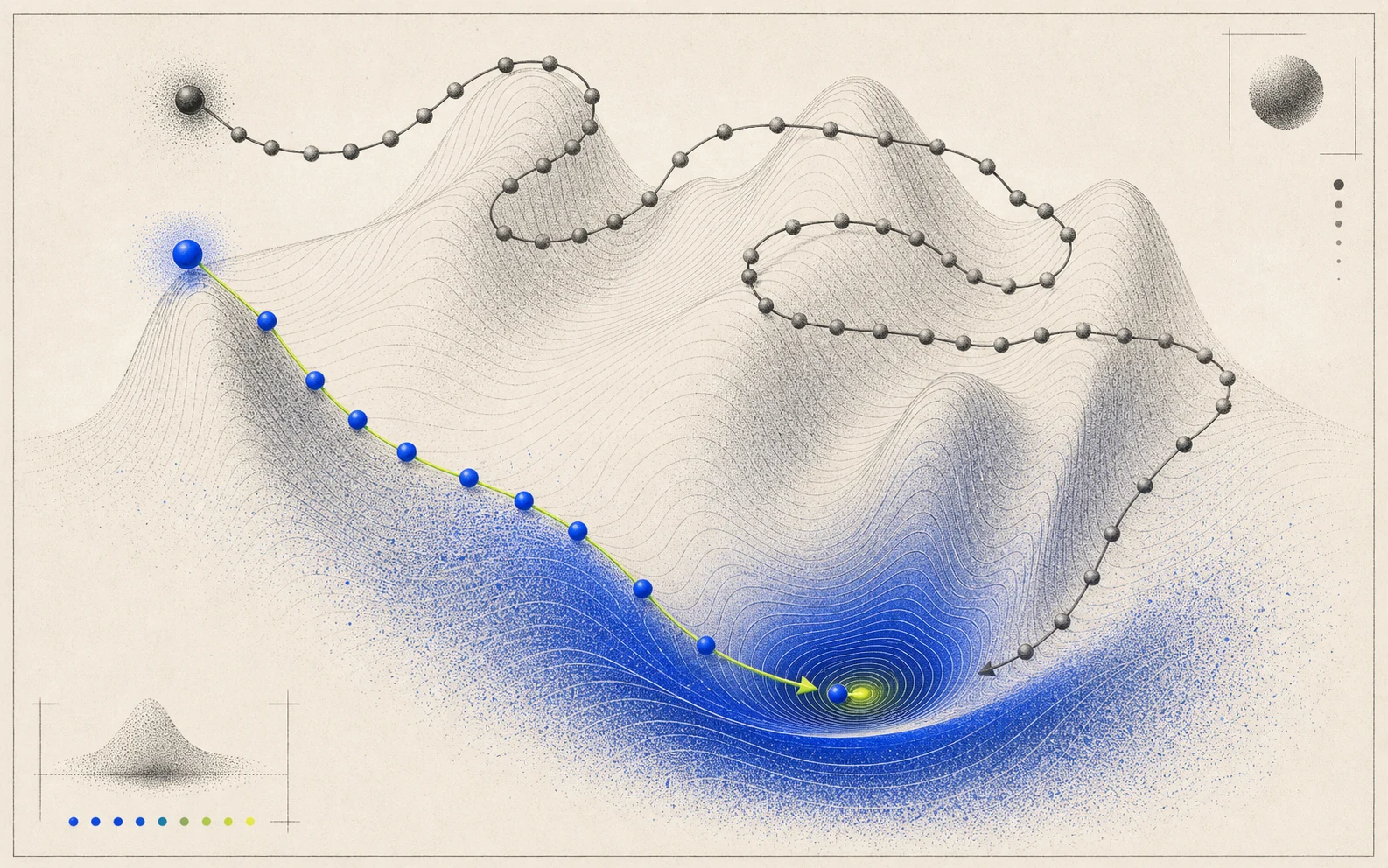
Short route
Useful tokens move directly toward solved work.02
Looping route
Extra text can circulate without buying correctness.03
Budget funnel
Efficiency asks how much solved work each generated token buys.How to read it
Budget accounting
Efficiency asks how much solved work each generated token buys, not whether the visible trace merely looks short.

Efficiency view
Solved work divided by generated text.
The metric is not a moral preference for short answers. It is a way to ask when additional reasoning text buys reliability, and when it only burns inference budget.
S
Correctness
Whether the final answer is valid under the benchmark extractor.T
Generated length
The visible output-token budget spent by the model.E
Efficiency
Correct answers produced per shared generated-token budget.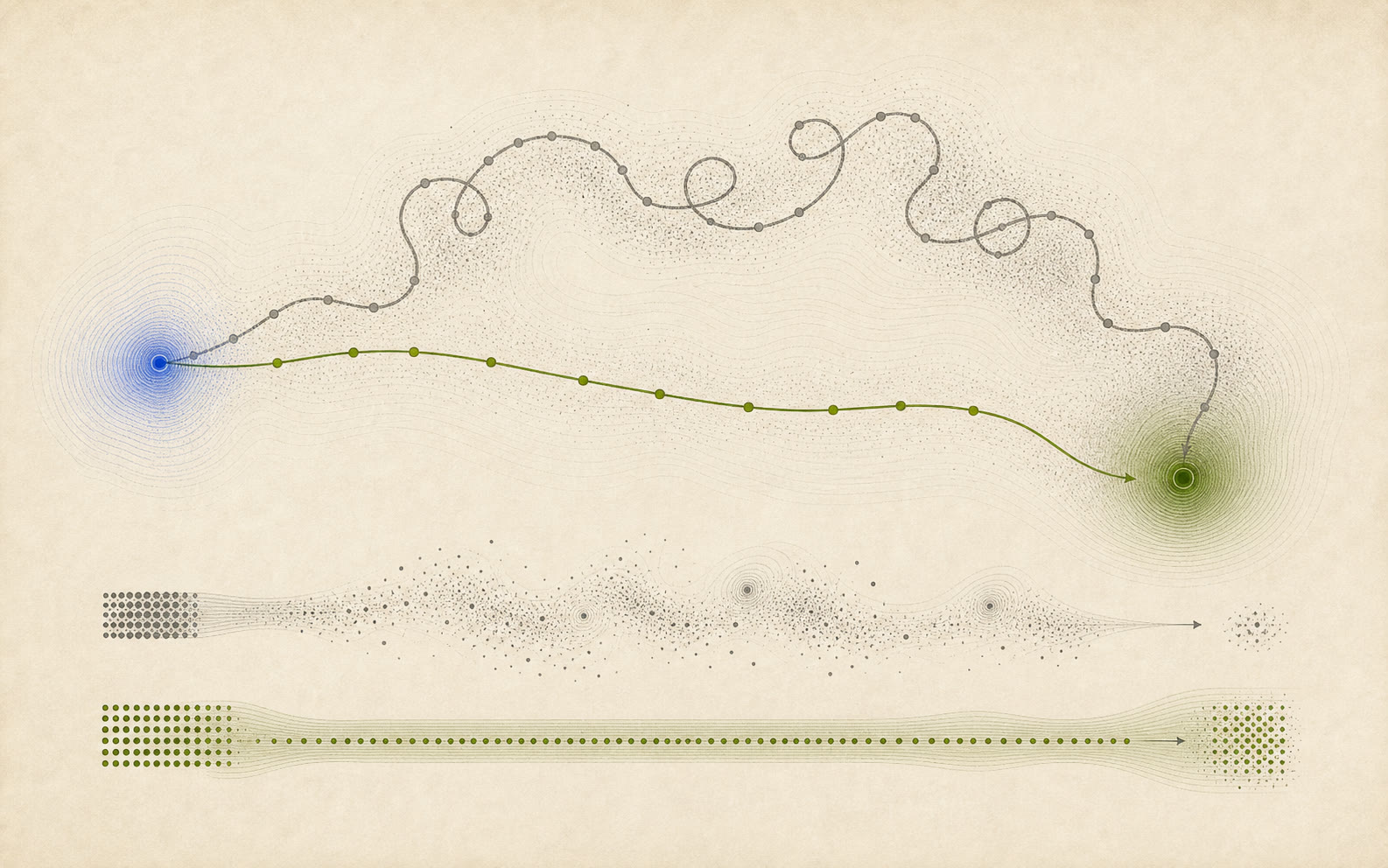
Main insight
Accuracy can tie while the budget story diverges.
Efficiency rankings can diverge from plain accuracy rankings.
Token budget matters most when models deliberate, self-correct, or loop.
Controlled tasks make it possible to ask where extra tokens buy accuracy and where they are wasted.
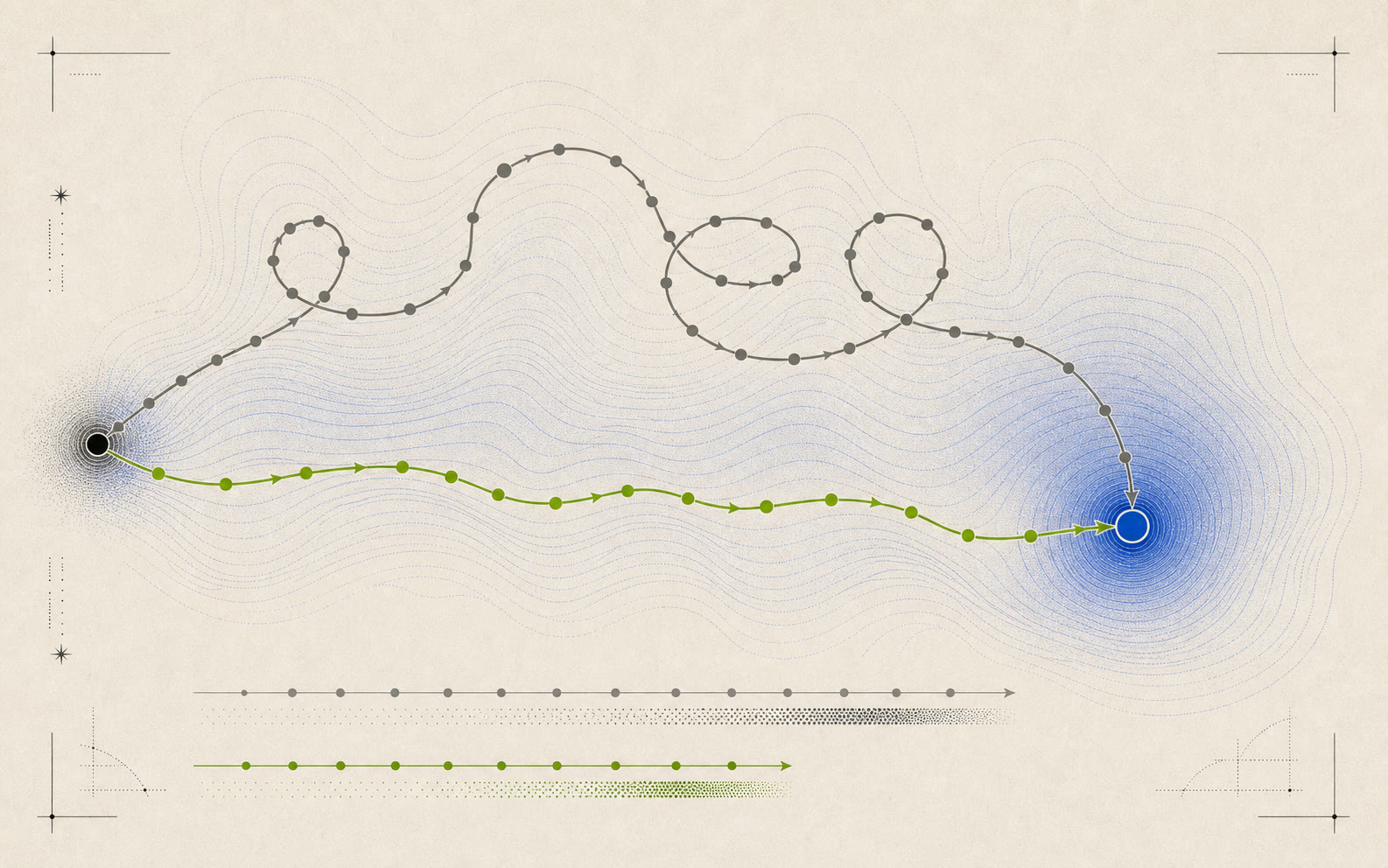
What it separates
Same score, different route
Two systems can land on similar accuracy while one burns budget through loops and detours.
This workshop paper introduced the first compact version of the reasoning-efficiency framing: evaluate reasoning not only by correctness, but by how much generated output budget is spent to obtain it.
Back to research overview