03
Diagnostic regimesResearch project
Beyond Accuracy
Beyond Accuracy: Decomposing the Reasoning Efficiency of LLMs
An accounting protocol for why reasoning is inefficient
Core question
When a reasoning model is inefficient, is it failing by truncation, by wrong completed answers, or by spending too much text relative to the work?
01
Completion layer
Did the model finish inside the context and output budget?02
Logic layer
Given completion, was the answer actually correct?03
Overhead layer
How much extra text was spent relative to the work?How to read it
Layered accounting
Completion, logic, overhead, and workload coupling are checked as separate layers before interpreting efficiency.
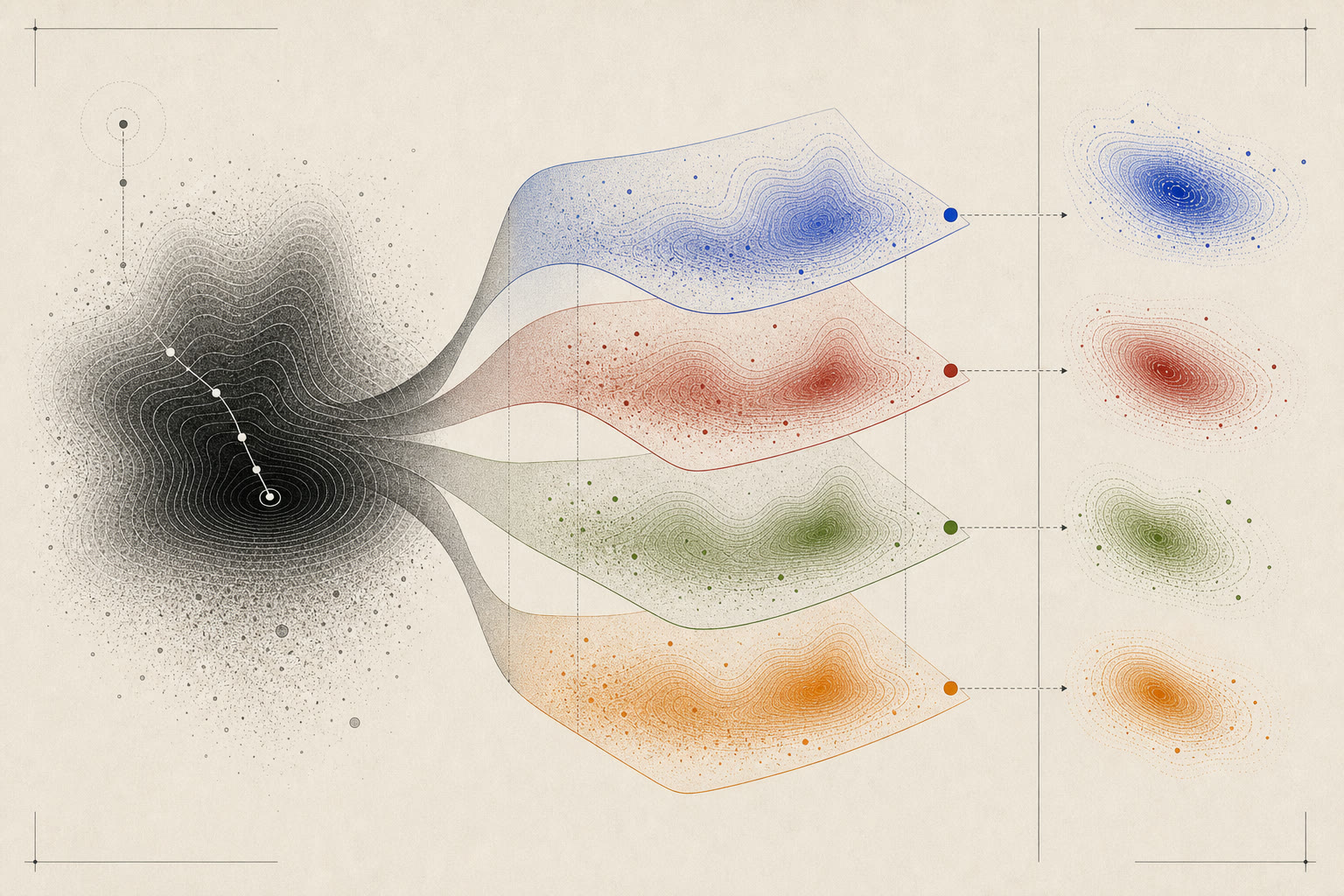
Accounting protocol
Split one bad number into its causes.
The page visual is a peeled reasoning landscape: each layer asks a different diagnostic question before the final efficiency score is interpreted.
r_ctx
Completion
Did the model finish within the stated output budget?r_logic
Conditional correctness
Given clean completion, did the model answer correctly?VO
Mean overhead
How many generated tokens were spent per unit of task-implied work?
Diagnostic regimes
Same accuracy, different repair strategy.
Efficiency and mean overhead rankings transfer more strongly than accuracy across several reasoning benchmarks.
Many low-efficiency models are logic-limited, while others are context-limited by truncation or verbosity-limited by overhead.
CogniLoad shows that long sequential context is the strongest efficiency stressor in the suite.
What it separates
Repair regimes
Context-limited, logic-limited, verbose, and balanced systems call for different interventions.
Beyond Accuracy turns token efficiency from a scalar leaderboard into a diagnostic protocol. It works for open and closed models because the core layer needs only correctness, truncation status, and generated-token counts.
Back to research overview